










Claude 3.5 Sonnet Unveiled
Anthropic has introduced Claude 3.5 Sonnet, the latest AI model that surpasses its predecessors and competitors like OpenAI’s GPT-4 Omni. This model is available for free on Claude.ai and the Claude iOS app. It can also be accessed via the Anthropic API, Amazon Bedrock, and Google Cloud’s Vertex AI. The pricing is set at $3 per million input tokens and $15 per million output tokens. Moreover, the model features a 200,000-token context window.
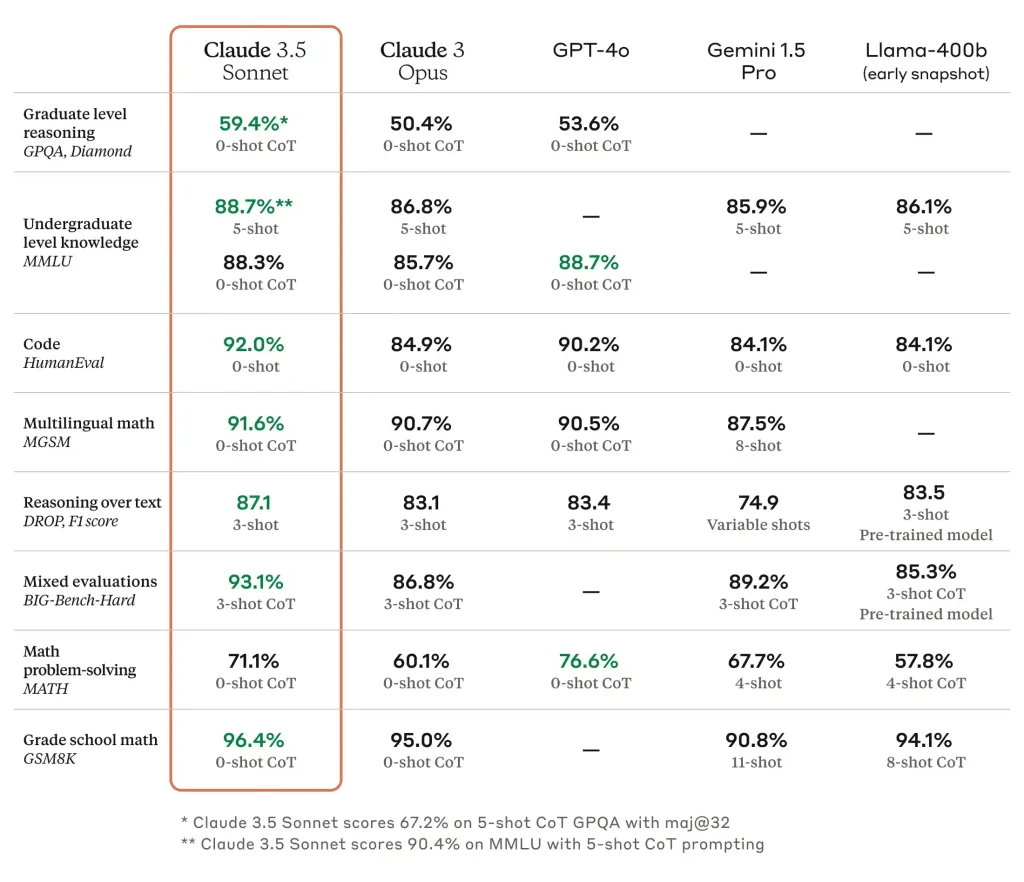
Benchmark Achievements
Claude 3.5 Sonnet establishes new benchmarks in graduate-level reasoning (GPQA), undergraduate-level knowledge (MMLU), and coding proficiency (HumanEval). It shows significant improvements in understanding nuance, humor, and complex instructions. The model generates high-quality content with a natural tone. Operating at twice the speed of Claude 3 Opus, it is ideal for complex tasks like context-sensitive customer support and multi-step workflows.
Performance Highlights
“In an internal agentic coding evaluation, Claude 3.5 Sonnet solved 64% of problems, outperforming Claude 3 Opus, which solved 38%.”
The model can independently write, edit, and execute code, proving effective for updating legacy applications and migrating codebases. Additionally, it excels in visual reasoning tasks, such as interpreting charts and graphs. Furthermore, it can accurately transcribe text from imperfect images, benefiting sectors like retail, logistics, and financial services.
New Features and Safety Measures
Anthropic has also introduced Artifacts, a new feature on Claude.ai that allows users to generate and edit content like code snippets, text documents, or website designs in real time. This feature signifies Claude’s evolution from a conversational AI to a collaborative work environment. There are plans to support team collaboration and centralized knowledge management in the future.
Anthropic emphasizes its commitment to safety and privacy. Claude 3.5 Sonnet has undergone rigorous testing to reduce misuse. External experts, including the UK’s Artificial Intelligence Safety Institute (UK AISI), have evaluated the model. Additionally, Anthropic has integrated feedback from child safety experts to update its classifiers and fine-tune its models. The company assures that it does not train its generative models on user-submitted data without explicit permission.
Future Developments
Looking ahead, Anthropic plans to release Claude 3.5 Haiku and Claude 3.5 Opus later this year. Additionally, new features like Memory will enable Claude to remember user preferences and interaction history.
The post Claude 3.5 sets new AI benchmarks, beating GPT-4o in coding and reasoning appeared first on CryptoSlate.




